2020 年百度之星·程序设计大赛

然而,今天又是被高中生暴打的一天…rank1177走了
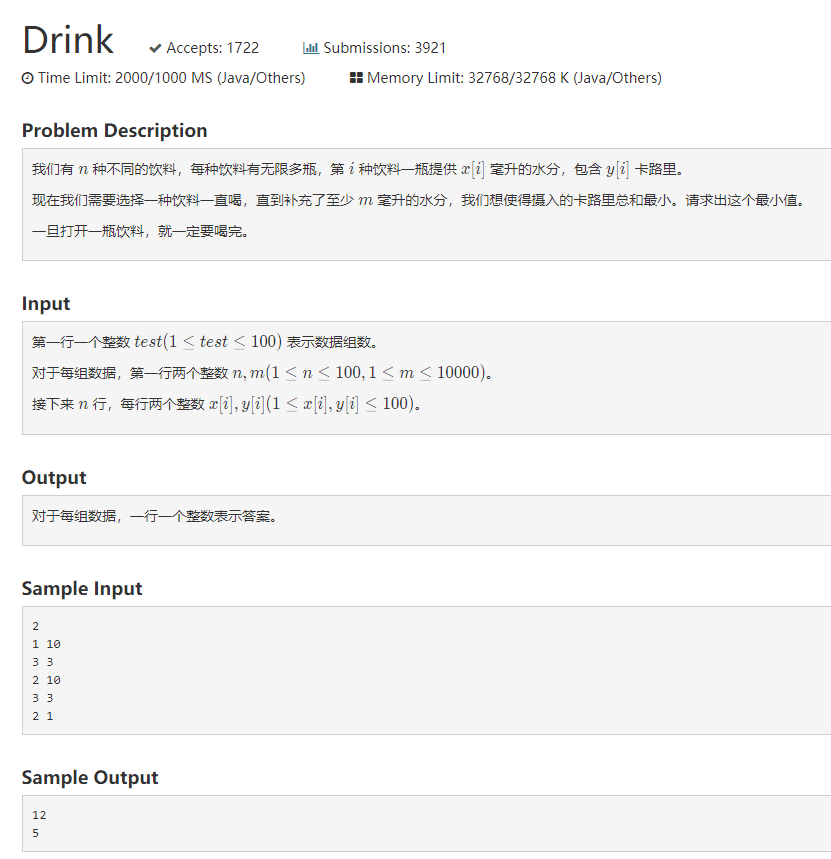
1001 drink
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
class drink {
public:
int x;
int y;
drink(int _x, int _y) : x(_x), y(_y) {}
};
int main(){
int test;
cin >> test;
int n, m; // drinksN, water
for (int i = 0; i < test; ++i) {
cin >> n >> m;
vector<drink> drinks;
int x, y;
for (int j = 0; j < n; ++j) {
cin >> x >> y;
drinks.push_back(drink(x, y));
}
// main
int min = INT_MAX;
for (drink d : drinks) {
int number = m / d.x;
int rest = m % d.x;
if (rest != 0)
number++;
int res = number * d.y;
if (res < min)
min = res;
}
cout << min << endl;
}
return 0;
}
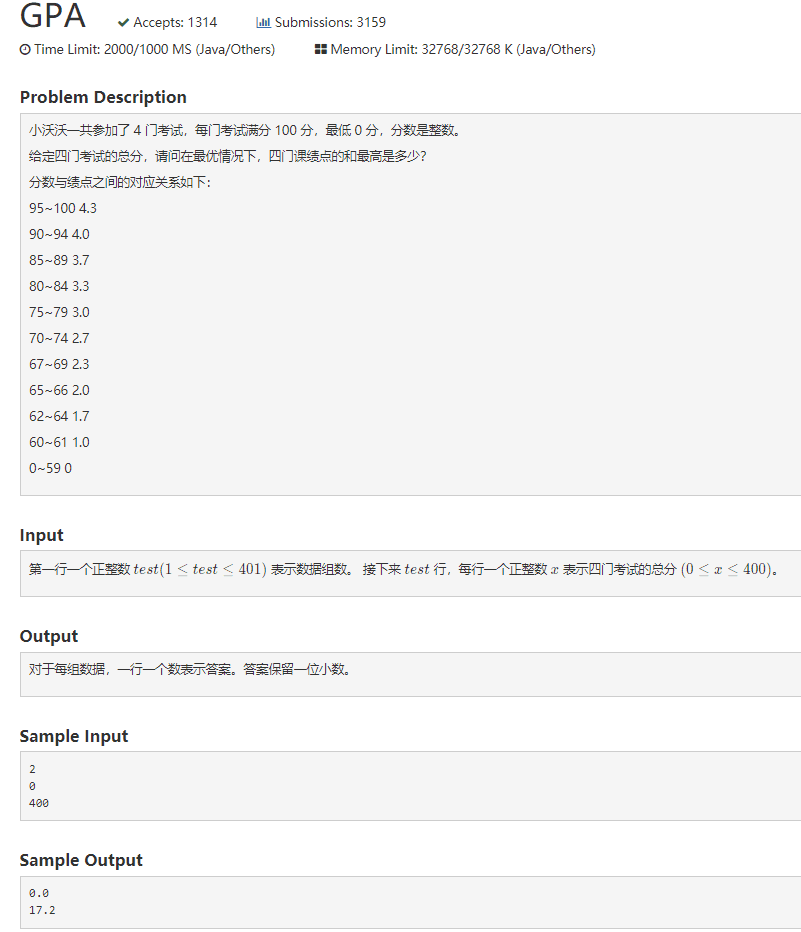
1002 GPA
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
using namespace std;
double Max;
int scores[11] = { 95,90,85,80,75,70,67,65,62,60,0 };
double gpa[11] = { 4.3,4.0,3.7,3.3,3.0,2.7,2.3,2.0,1.7,1.0,0 };
double calc(double score){
if (score >= 95)
return 4.3;
else if (score >= 90)
return 4.0;
else if (score >= 85)
return 3.7;
else if (score >= 80)
return 3.3;
else if (score >= 75)
return 3.0;
else if (score >= 70)
return 2.7;
else if (score >= 67)
return 2.3;
else if (score >= 65)
return 2.0;
else if (score >= 62)
return 1.7;
else if (score >= 60)
return 1.0;
else
return 0.0;
}
void dfs(int cur, int sum, double score){
if (sum < 0)
return;
if (cur == 3){
Max = max(Max, calc(sum) + score);
return;
}
for (int j = 0; j < 11; j++)
dfs(cur + 1, sum - scores[j], score + gpa[j]);
}
int main()
{
int test, n;
cin >> test;
for (int i = 0; i < test; ++i) {
cin >> n;
Max = 0;
dfs(0, n, 0);
//cout << Max << endl;
printf("%.1lf\n", Max);
}
}
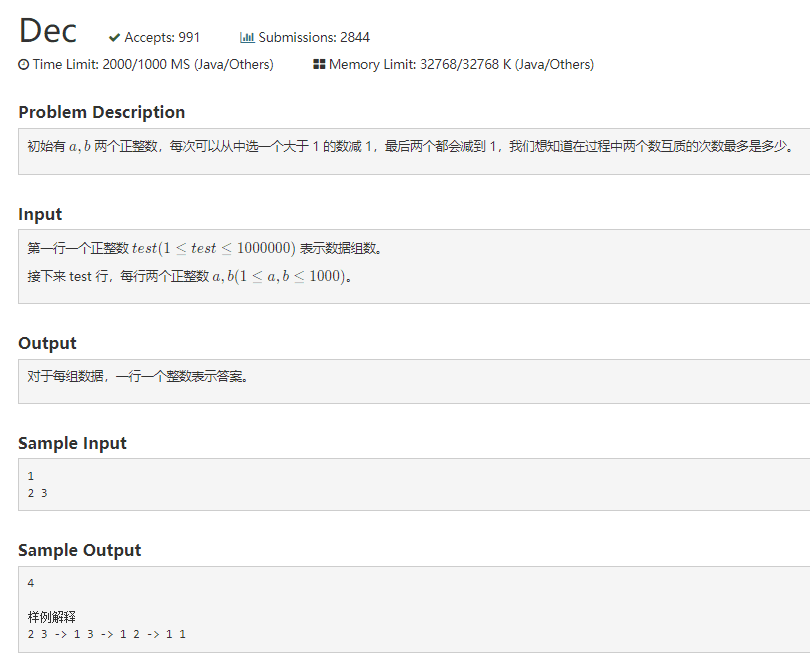
1003 Dec
不加前面的tie就会TLE,也不知道为啥,也许是输入输出太多了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
using namespace std;
int gcd(int a, int b) {
if (b == 0)
return a;
return gcd(b, a % b);
}
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int test, a, b;
cin >> test;
vector<vector<int>> v(1001, vector<int>(1001, 0));
for (int i = 1; i <= 1000; ++i) {
for (int j = 1; j <= 1000; ++j) {
if (gcd(i, j) == 1) {
v[i][j] = max(v[i][j - 1], v[i - 1][j]) + 1;
}
else {
v[i][j] = max(v[i][j - 1], v[i - 1][j]);
}
}
}
for (int i = 0; i < test; ++i) {
cin >> a >> b;
if (a < b)
cout << v[a][b] << endl;
else
cout << v[b][a] << endl;
}
return 0;
}
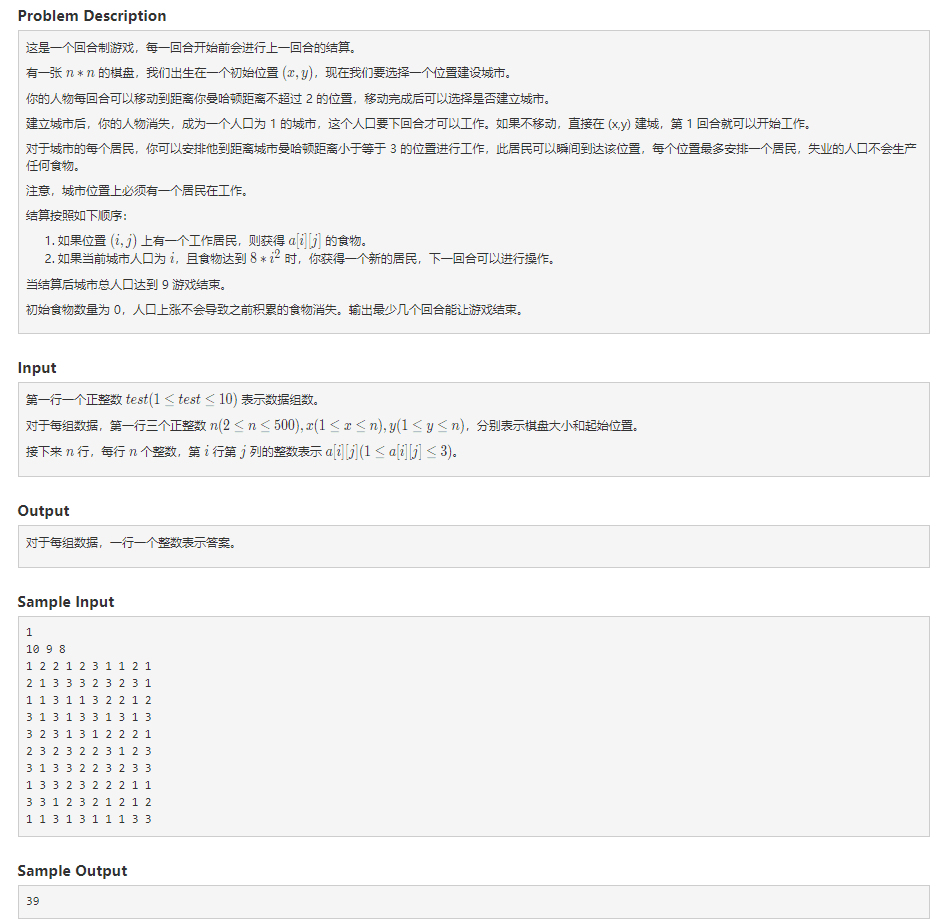
1004 Civilization
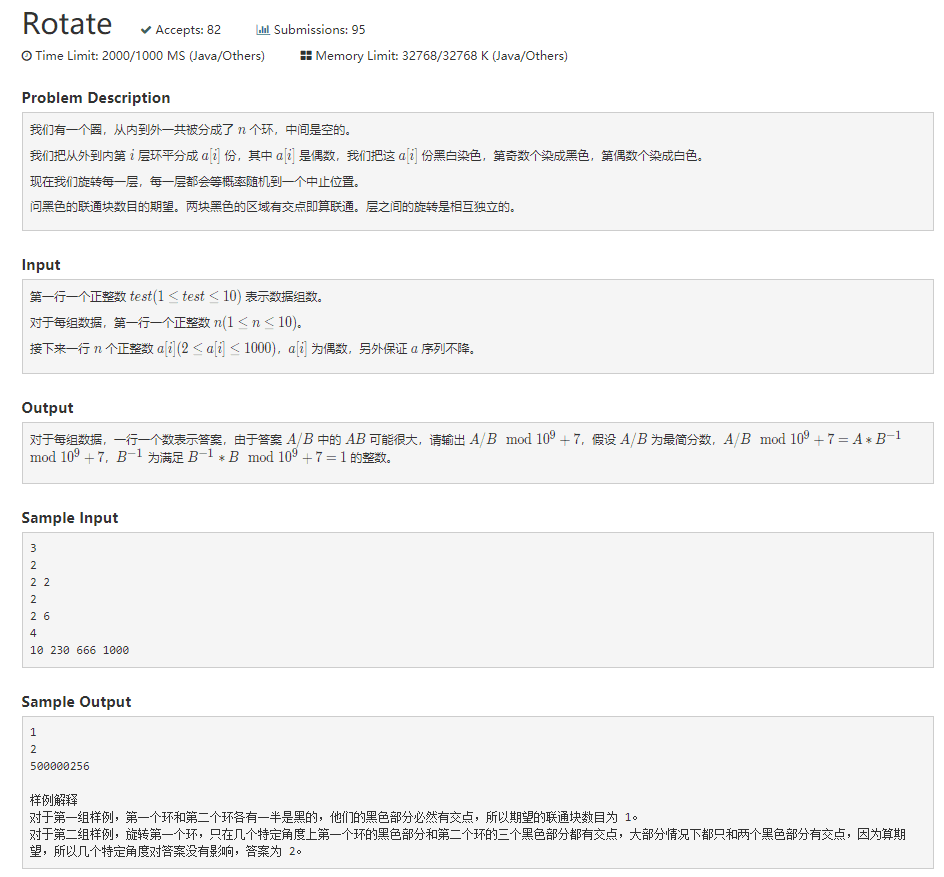
1005 Rotate
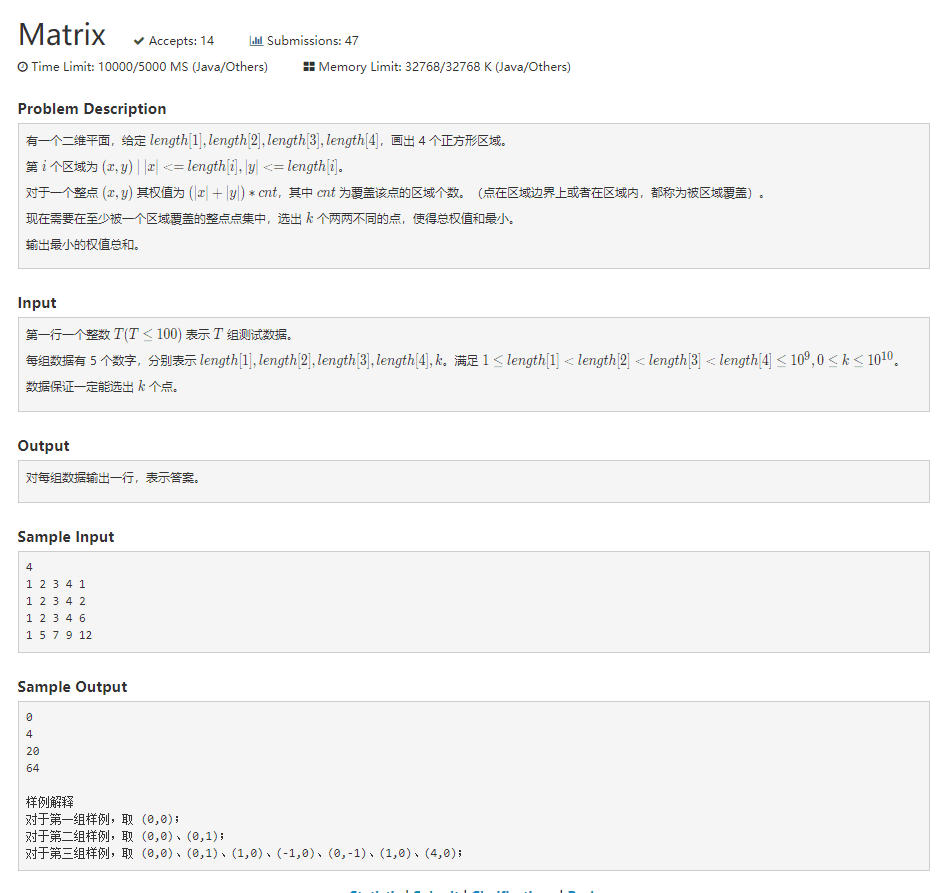
1006 matrix
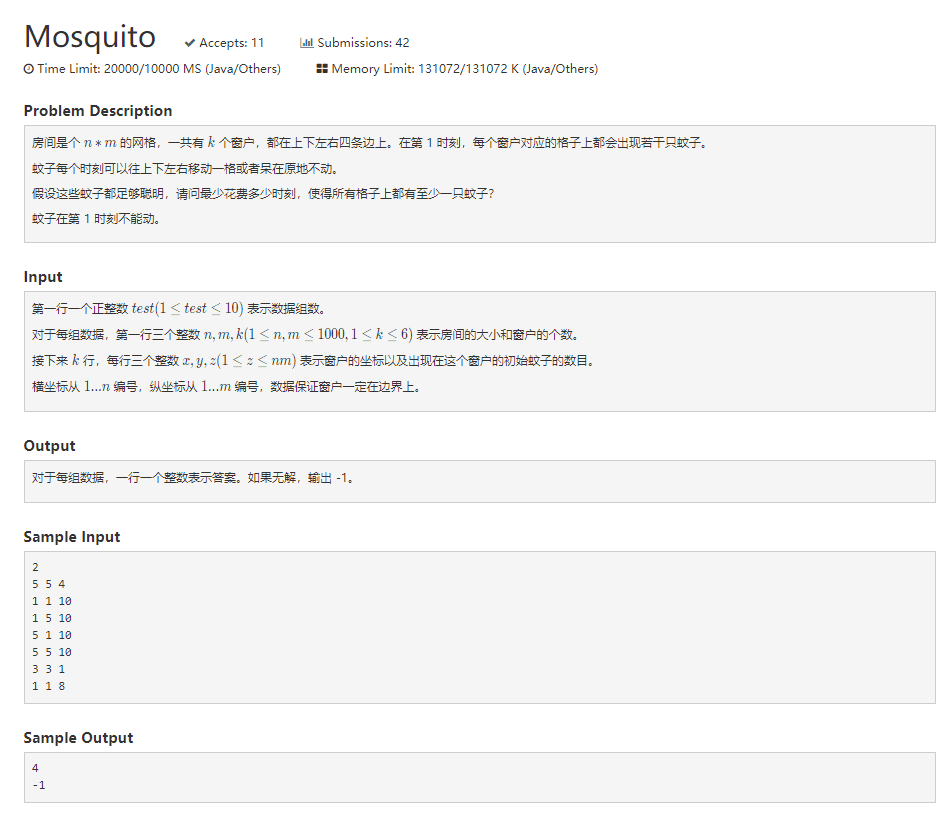
1007 Mosquito
1008 Function